
AI17: Designing for humans vs AI agents
What we need is different from what LLMs need


When I create an AI agent, I would usually print the LLM’s responses, tool calls, tool results, and other logs to the Terminal. This is so that I know what is happening while the agent is running.
For example, I recently wrote a script to browse Product Hunt for the recent top launches and message me the summary in Slack. When the LLM uses the Browser Use tool to browse the web, I would print each completed step and the final result:
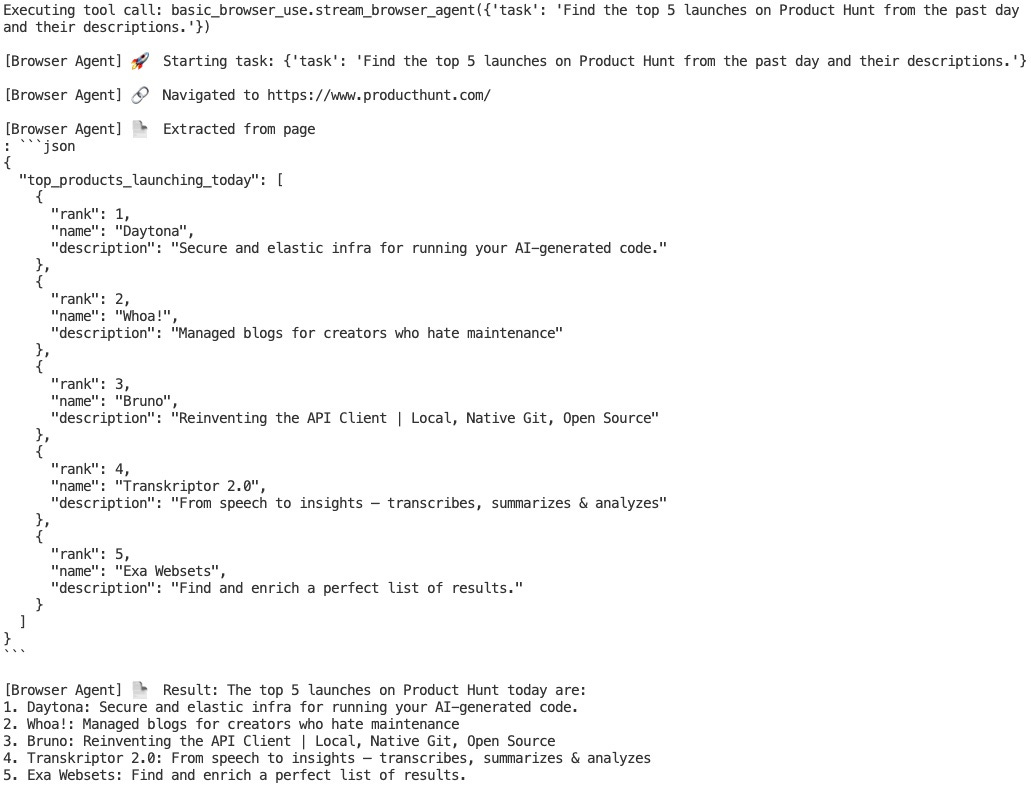
If something goes wrong somehow, I can terminate the script immediately and fix the issue.
But the printed logs are for humans.
Are they necessary for agents? In other words, should they be included in the chat history to generate the next response from the LLM?
Initially, I had thought it is useful to add all these logs into the chat history so that the LLM has full context. The more information, the better, right?
No. That’s not always true.
Here are some considerations:
Most importantly, will this information be useful to the agent? If the information doesn’t help with generating the next response, we should leave it out.
A long context can confuse the LLM. It might focus on the wrong part of the context and return an incorrect response.
The longer the context, the more tokens there are, and the higher the cost. If we want to save money, we should exclude unnecessary information from the context.
In the example above, the final result (the list of top launches on Product Hunt) is the only information the LLM needs to generate the next response, which is to call the Slack tool with the information to send the Slack message. The steps taken to get the result are arguably unnecessary. So, I should append the final result but not the steps to the chat history for generating the next response.
But if there was an error and the Browser Use tool cannot get the requested information, I should append the error to the chat history. For example, the error might be that the website that it visited blocks bots and it cannot get the required information. The error message can then help the LLM generate a better response, such as using another tool that could visit the website.
Here’s another example:
We have a Python sandbox tool, which allows LLMs to write and execute Python code in a sandbox. I was playing with it recently to plot a graph:

The logs above are essentially:
The LLM’s text response that it will create a chart with the code sandbox
The LLM’s tool call with the generated code to create the chart
The logs of the code sandbox when it parsed the input code, loaded packages, executed the code, which include printed messages and the final output
This information is helpful for me to verify that the script is working and to monitor the progress. But again, this is for me, the human, not the agent.
The huge chunk of [deno log] about parsing the input code is not necessary in the chat history because the chat history already has the input code when the LLM responded with the generated code.
The logs, “Loading X, Y, Z”, are also unnecessary in the chat history because those are what the Python sandbox tool is doing, which the LLM cannot influence. The LLM can only change the generated code that it passes to the Python sandbox.
Because of that, if the generated Python code returns an error, the error message should be appended to the chat history so that the LLM will “see” the error and try to generate a new piece of code that doesn’t have the issue. This essentially enables the agent to self-correct without needing us developers or our users to jump in.
In summary, humans and agents require different information.
We humans might want as much information as possible to stay on top of things. Developers want the information to debug issues while users want it to gain trust in the system.
But we should only provide relevant information to the agent (ie, append it to the chat history). If the tool use is successful, provide the result. If the tool use failed, provide the error message and any useful context so that the LLM can generate a better tool call to complete the task.
Jargon explained
Deno: Deno is a sandbox to run JavaScript and TypeScript code securely. The code cannot touch files, access the internet, or read environment variables unless explicitly granted those rights.
Pyodide: Pyodide is like a mini-Python that can be run in the browser, like how ChatGPT can run Python code in its web app. It can also be run in JavaScript environments, like Deno, which allows desktop apps to run Python code. But because it’s a lite version of Python, Pyodide doesn’t support all Python libraries. Many popular ones are, though.
Enumerate cannot be used on an async generator: Enumerate in Python allows us to get the items in an iterable, such as a list or tuple, and their respective position without manually counting the position. But it cannot be used on the result of an async generator because it only works for synchronous iterables.
# sync generator
for i, output in enumerate(sync_generator(args)):
print(f"Step {i}: {output}")
# async generator
i = 0
async for output in async_generator(args):
print(f"Step {i}: {output}")
i += 1Interesting links
Running Python code in a Pyodide sandbox via Deno: We created our Python sandbox tool with reference to this article.
How Andrej Karpathy uses LLMs: He explains not just how he uses various LLMs and AI apps but also how the different modalities (text, audio, images) work. After watching this video, I updated my custom instructions and created an English-to-Chinese translation custom GPT.


