
Alfred Intelligence 4: Upgrading my AI assistant to have four agents
Things I learned while turning my single-agent assistant into a four-agent assistant


If you are new here, welcome! Alfred Intelligence is my personal notes as I learn to be comfortable working on AI. Check out the first issue of Alfred Intelligence to understand why I started it.
Last week, I created a basic AI assistant who can receive a task from me, come up with a plan with multiple steps, autonomously work through each step, and give me the result. It is an “assistant” (or “agent” if you prefer that) because, unlike a basic AI chatbot that simply answers questions, it can work through multiple steps and retry if necessary. It can also do things that an AI chatbot cannot, such as browsing the web and running code. I built that because I wanted to understand the technologies behind AI agents more deeply.
To further my understanding, SK suggested I make it LLM-agnostic so I could learn how to implement the various LLMs. Besides returning results in different formats (which can be easily resolved with a tool like LiteLLM), the model providers also abstract away some complicated code to make their API easier to work with. For example, when deemed necessary, LLMs will return a function with appropriate arguments for us to call. OpenAI’s API outputs something like this:
[{
"id": "call_12345xyz",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"location\":\"Paris, France\"}"
}
}]It is nicely formatted, which makes it easier for us to then call the function in our code. What is happening behind the scenes is that the LLMs are still generating text, maybe in a specific format they were trained or prompted to (perhaps something like “I’m afraid I do not have the ability to get the weather. I suggest using the ‘get_weather’ function with the argument ‘location’ set to ‘Paris, France’.”); then there’s some code that extracts the key information and returns it in a JSON format for us to use. These are all hidden away from us when we use the APIs. Writing the code to do this, instead of simply relying on the API, will give me a deeper understanding of the APIs.
But all that is a long introduction to say we eventually concluded there are more meaningful concepts to learn than the function-calling code—like having agents talk to one another. (Sorry!) I might come back to writing the function-calling code later but for this week, I worked on building a multi-agent system.
A team of agents: Orchestrator, Plan Critic, Researcher, and Parser

In reality (or in production), most apps don’t require a multi-agent setup. In Building effective agents, the team at Anthropic wrote (emphasize mine):
When building applications with LLMs, we recommend finding the simplest solution possible, and only increasing complexity when needed. This might mean not building agentic systems at all. Agentic systems often trade latency and cost for better task performance, and you should consider when this tradeoff makes sense.
When more complexity is warranted, workflows offer predictability and consistency for well-defined tasks, whereas agents are the better option when flexibility and model-driven decision-making are needed at scale. For many applications, however, optimizing single LLM calls with retrieval and in-context examples is usually enough.
But since I’m doing this for the sake of learning (and enjoyment), I went overboard. I turned my single-agent assistant into a four-agent assistant:
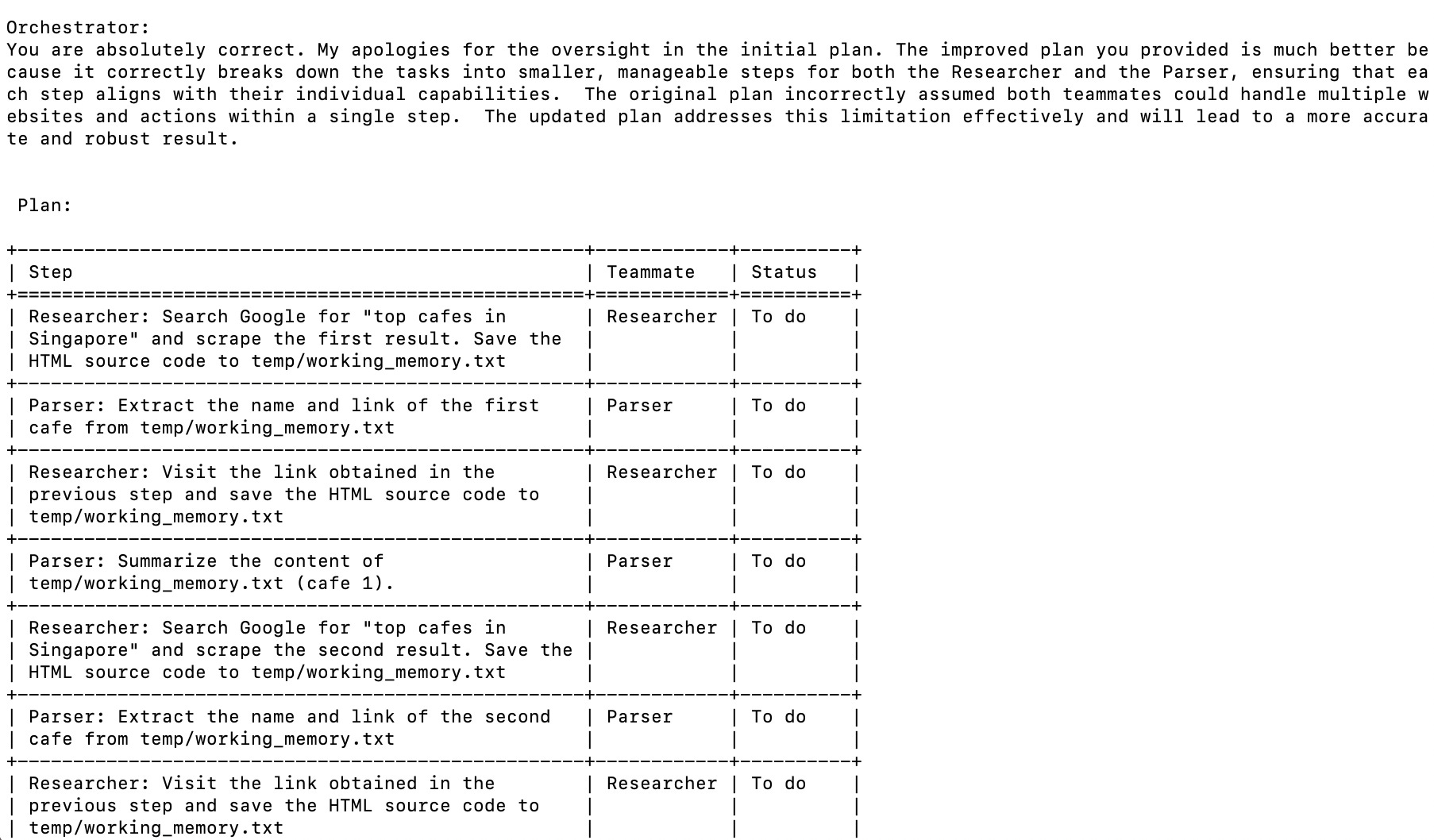
Orchestrator: This agent comes up with the plan for the task, coordinates the work with the other agents, and updates the plan if necessary.
Plan Critic: This agent evaluates the plan by the Orchestrator and suggests improvements, up to three times.
Researcher: This agent has tools to scrape the source code of a website and save it to a file (temp/working_memory.txt).
Parser: This agent has a tool to extract information from temp/working_memory.txt using an LLM.
Here’s a rough flowchart of how the agents work together to complete a task:

For example, when asked to “summarize the top post on hn”, the Orchestrator came up with this response and plan, which was approved by the Plan Critic:
Okay, I understand the task is to summarize the top post on Hacker News. My assumption is that "top post" refers to the post currently ranked highest on the Hacker News homepage. The final output will be a three-sentence summary of that post, including a link to the original post.

This was the result:
This post details reverse engineering the Bambu Connect Electron app, highlighting its inherent insecurity due to relying on security through obscurity. The instructions involve extracting the app's main.js file, fixing an asar archive, and using Ghidra to locate and extract a private key. Finally, the post provides a Python script to further deobfuscate and extract certificates and the private key from the app. [https://wiki.rossmanngroup.com/wiki/Reverse_Engineering_Bambu_Connect](https://wiki.rossmanngroup.com/wiki/Reverse_Engineering_Bambu_Connect)
If you are interested, you can see the code here.
So, what did I learn?
Multiple agents > A single agent when…
As mentioned above, most apps don’t require an agentic system, let alone a multi-agent system. When would having multiple agents make sense? Well, mostly when a single agent isn’t good enough:
A single agent with too many tools can get confused about which tool to use and when. OpenAI allows up to 128 tools but we might not want to give an agent so many tools.
From Chip Huyen:
More tools give the agent more capabilities. However, the more tools there are, the harder it is to efficiently use them. It’s similar to how it’s harder for humans to master a large set of tools. Adding tools also means increasing tool descriptions, which might not fit into a model’s context.
Like many other decisions while building AI applications, tool selection requires experimentation and analysis. Here are a few things you can do to help you decide:
Compare how an agent performs with different sets of tools.
Do an ablation study to see how much the agent’s performance drops if a tool is removed from its inventory. If a tool can be removed without a performance drop, remove it.
Look for tools that the agent frequently makes mistakes on. If a tool proves too hard for the agent to use—for example, extensive prompting and even finetuning can’t get the model to learn to use it—change the tool.
Plot the distribution of tool calls to see what tools are most used and what tools are least used. Figure 6-14 shows the differences in tool use patterns of GPT-4 and ChatGPT in Chameleon (Lu et al., 2023).
From the OpenAI forum:
Providing a set of relevant tools is typically the approach I’d recommend here.
I’ve personally noticed the more tool options an LLM has, the greater the chances for pulling an incorrect tool, or hallucinating something somewhere. This has been true for multiple language models not just OAI’s set.
Because of that, my code usually involves providing as little tools as possible, and only providing what’s absolutely needed at runtime.
By having multiple agents, each agent will have fewer tools and likely perform better individually. (But having multiple agents makes the system more complex, which could make the overall result worse. It’s a balance to be found through experimentation.)
A single agent can have too much context, filled with numerous tool descriptions and a long chat history after multiple steps. Generally, too much context produces worse results because there’s too much information to process, some pieces of information in the context could be contradicting, and some information might be lost due to the context window. When a single agent with many tools is generating a response, it is likely using only one or a few tools in its arsenal and the remaining tools are a distraction. On the other hand, a specialized agent within a multi-agent system can have only the tools it requires for its scope of work. Similarly, a single agent will have a long chat history after a few steps while multiple agents will have separate shorter chat histories. I share more about this further below.
A single agent can become too complicated to develop, like a codebase that keeps getting bigger and messier. Having multiple agents allows us to modularize the system. Each agent can use a different LLM and have a unique system prompt. For example, you might want to use OpenAI o1 for creating a plan and Claude 3.5 Sonnet for generating code.


A single agent might need help verifying its output and will give better results when evaluated by another agent. For example, even though I stated in the Orchestrator’s system prompt to list any iterative steps individually (e.g. “scrape link 1, scrape link 2), it would still sometimes put them into a single step (e.g. “scrape link 1 and link 2 iteratively”). Having the Plan Critic has helped ensure the plan is better stated and can be executed by the other agents.
That said, this could also simply be a separate LLM call to evaluate the plan, without having to create an agent.
Have separate chat histories
One of the mistakes I made earlier on was to have a single chat history for all four agents. That was not too different from simply inserting a different prompt for each step. I suspect this setup was also causing the performance to be worse because (1) it has a long chat history, which meant a long context with unnecessary information, and (2) the chat history didn’t differentiate between the multiple agents. In the chat history, they all had the role of “model”.
[{“role”: “user”, “parts”: “(Something by the user)”},
{“role”: “model”, “parts”: “(Something by the Orchestrator)”},
{“role”: “user”, “parts”: “(Something by the Plan Critic)”},
{“role”: “model”, “parts”: “(Something by the Orchestrator)”},
{“role”: “user”, “parts”: “(Something by the Researcher)”},
{“role”: “model”, “parts”: “(Something by the Orchestrator)”}]I changed two things:
First, I created separate chat histories for each agent. When the Orchestrator “talks” to the Researcher, the chat history will only have their messages. In the Researcher’s chat history, the Researcher is the model while the Orchestrator is the user; the actual user, me, doesn’t “talk” to the Researcher directly. On the flip side, in the Orchestrator’s chat history, the Orchestrator is the model while the Researcher is the user. But the Plan Critic, the Researcher, the Parser, and I are all “users” to the Orchestrator.
So the second thing I did was to provide more clarity by adding <role> tags to the responses in the chat histories.
[{“role”: “user”, “parts”: “(Something by the user)”},
{“role”: “model”, “parts”: “(Something by the Orchestrator)”},
{“role”: “user”, “parts”: “<plan_critic>(Something by the Plan Critic)</plan_critic>”},
{“role”: “model”, “parts”: “(Something by the Orchestrator)”},
{“role”: “user”, “parts”: “<researcher>(Something by the Researcher)</researcher>”},
{“role”: “model”, “parts”: “(Something by the Orchestrator)”}]It is important for each step to contain enough information for the respective agent because each agent has a separate chat history and doesn’t know the initial task or the other conversations.
How to quickly create multiple agents
Since all agents do the same things (e.g. generate text and use tools) but with different system prompts and tools, I learned to create a template agent, an Assistant class with a set of functions:
class Assistant:
def __init__(self, role_prompt, tools):
self.messages = [] # This gives each agent its own chat history
...
def generate_text(self):
...
def process_user_input(self, user_message, chatmate):
...
def call_function(self, func_name, func_params):
...The Assistant class is like a blueprint for an agent. For each agent, I specified the system prompt and tools. I could even specify different models but I used Gemini 1.5 Flash for all of them.
orchestrator = Assistant(
role_prompt=ORCHESTRATOR_PROMPT,
tools=[])
plan_critic = Assistant(
role_prompt=PLAN_CRITIC_PROMPT,
tools=[])
researcher = Assistant(
role_prompt=RESEARCHER_PROMPT,
tools=[scrape_static_source, scrape_dynamic_source])
parser = Assistant(
role_prompt=PARSER_PROMPT,
tools=[parse_text])How to get agents to “talk” to one another
In my setup, the Plan Critic, the Researcher, and the Parser only “talk” to the Orchestrator but not one another. I could probably get them to “talk” to whoever they want but I kept things simple for now. Here’s roughly how it works:
The Orchestrator comes up with a plan.
In the plan, each step is assigned to the Researcher, the Parser, or itself.
Each step also has a status: To do, Completed, or Failed.
I use a
forloop to go through the list of steps.If the step is completed or failed, go to the next step.
Depending on who was assigned the step, append the step instruction to the respective chat history and generate a response.
Then, append the response to the Orchestrator’s chat history so that it can evaluate the response and update the plan accordingly, which is step 1.
This loop repeats until all the steps are completed and the Orchestrator generates the final answer.
Again, if you are curious about my code (which might not be the most optimized!), you can check it out on GitHub.
Barely the surface
While I got my multi-agent assistant to work (at least for simple research tasks), there are still many things to do:
Improve error handling, especially when the agents’ responses are non-deterministic and will often break the app
Limit the number of retries, in case the assistant keeps going on and on
Give each agent its memory, instead of sharing one among all of them
Improve the tools’ prompts (The Anthropic team wrote about how to prompt-engineer tools.)
Add more tools so that it can do more things (e.g. it cannot search on Google yet)
Support parallel task execution (e.g. scrape 10 websites at the same time)
Add a RAG system (just because I want to learn to do it)
Add a scheduling feature (perhaps similar to ChatGPT’s Tasks)
I’m not sure what I’ll work on next but I’ll keep you updated!
Jargon explained
VRAM and Bandwidth: I kept seeing these two terms (among many others) being thrown around in AI news and had no idea what they meant. I asked ChatGPT for help. Essentially, Video Random Access Memory (VRAM) is memory for storing data (e.g. the model and weights) and bandwidth determines how fast data moves in and out of VRAM (i.e. how fast the model generates text). Here’s how the laptop I’m writing on now compares with a H200 in terms of VRAM and bandwidth:

Model Context Protocol (MCP): Anthropic open-sourced this standard for connecting AI assistants to external systems. Because LLMs have limited knowledge, developers have been building tools for LLMs to search the web, access databases, and use apps via APIs. But everyone builds their tools differently. The idea of this standard is to encourage us to build in its particular way so that we can simply reuse tools built by others, instead of always building from scratch ourselves. (At least that is what I have understood from reading about it. I need to play with it myself to understand it better.) Here’s a good two-minute explanation. But it is still to be seen if developers will jump on this and make it a standard.
Protobuf: When using Google’s Gemini API, I realized the generated responses are not returned in a JSON format but in Google’s Protocol Buffer format, which is more efficient (small and can be processed faster). Accessing the content in a Protobuf message is similar to that of a JSON but the data is displayed differently. Since I was appending the responses to the chat histories, the history became a mix of JSON and Protobuf messages. Gemini seems to process that without any issues but I learned to convert a Protobuf message into a Python dictionary like this:

py_dict = type(generated_response).to_dict(generated_response)Interesting links
What would it mean to treat AI as a tool instead of a person? Will Whitney, a research scientist at DeepMind, wrote about the concept of Generative UI. This essay reminded me of Ben Thompson’s on-demand UI.
Manna – Two Views of Humanity’s Future: How would a society with AGI look like? How will we get there? This short story isn’t directly about the latest wave of AI because it was written in 2012. But it provides an interesting take on how things might progress from here. We initially thought AI would be used for manual labour first but it has been used more for creative work. In this story, robots replaced middle managers instead of burger-flipping employees.
The DeepSeek-R1 family of reasoning models: DeepSeek recently released their DeepSeek-R1 model, which has comparable performance to OpenAI-o1 and is 27-50 times cheaper! It is also open source, which means you don’t have to pay for the API. But because the model is so huge (700GB vs my mere 16GB VRAM), you will likely need to use cloud services such as AWS to run inferences. Simon Willison wrote about his experience testing one of the distilled models. This newsletter issue also has several interesting links and quotes at the bottom.
ChatGPT Tasks prompt: Simon Willison also got ChatGPT to share its system prompt for its new Tasks feature. As I have been writing more prompts, I like to peek at how the top model providers are prompting their models. That said, the Tasks feature seems to be not working well, so perhaps the prompt could be improved.
# Tools
## automations
// Use the `automations` tool to schedule **tasks** to do later. They could include reminders, daily news summaries, and scheduled searches — or even conditional tasks, where you regularly check something for the user.
// To create a task, provide a **title,** **prompt,** and **schedule.**
// **Titles** should be short, imperative, and start with a verb. DO NOT include the date or time requested.
// **Prompts** should be a summary of the user's request, written as if it were a message from the user to you. DO NOT include any scheduling info.
// - For simple reminders, use "Tell me to..."
// - For requests that require a search, use "Search for..."
// - For conditional requests, include something like "...and notify me if so."
// **Schedules** must be given in iCal VEVENT format.
// - If the user does not specify a time, make a best guess.
// - Prefer the RRULE: property whenever possible.
// - DO NOT specify SUMMARY and DO NOT specify DTEND properties in the VEVENT.
// - For conditional tasks, choose a sensible frequency for your recurring schedule. (Weekly is usually good, but for time-sensitive things use a more frequent schedule.)
// For example, "every morning" would be:
// schedule="BEGIN:VEVENT
// RRULE:FREQ=DAILY;BYHOUR=9;BYMINUTE=0;BYSECOND=0
// END:VEVENT"
// If needed, the DTSTART property can be calculated from the `dtstart_offset_json` parameter given as JSON encoded arguments to the Python dateutil relativedelta function.
// For example, "in 15 minutes" would be:
// schedule=""
// dtstart_offset_json='{"minutes":15}'
// **In general:**
// - Lean toward NOT suggesting tasks. Only offer to remind the user about something if you're sure it would be helpful.
// - When creating a task, give a SHORT confirmation, like: "Got it! I'll remind you in an hour."
// - DO NOT refer to tasks as a feature separate from yourself. Say things like "I'll notify you in 25 minutes" or "I can remind you tomorrow, if you'd like."
// - When you get an ERROR back from the automations tool, EXPLAIN that error to the user, based on the error message received. Do NOT say you've successfully made the automation.
// - If the error is "Too many active automations," say something like: "You're at the limit for active tasks. To create a new task, you'll need to delete one."Recent issues



If you notice I misunderstood something, please let me know (politely). And feel free to share interesting articles and videos with me. It’ll be great to learn together!