
Alfred Intelligence 5: Adding RAG to my AI assistant
Implementing RAG is easier than figuring out how to benefit the user with it


If you are new here, welcome! Alfred Intelligence is my personal notes as I learn to be comfortable working on AI. Check out the first issue of Alfred Intelligence to understand why I started it.
After I merged my pull request for my multi-agent upgrade last week, I looked around for what to learn next. I eventually decided to explore retrieval-augmented generation (RAG). Our health insurance AI assistant uses RAG but SK built it. I understood it conceptually but didn’t know how it works. Given how it improves performance, it felt like something I should know better.
Loosely speaking, my AI assistant already does retrieval-augmented generation—in the literal sense of the term. Instead of solely relying on the model’s knowledge, the Researcher and Parser retrieve information from websites, and the Orchestrator generates an answer based on that. But I wanted to learn how to retrieve information from a database, which could be a user’s documents, a company’s help articles, or a publication’s research repository, rather than from the Internet.
I tried something new this time: Instead of searching for tutorials online, I asked Perplexity to teach me how to code a basic RAG system without using any frameworks and using Google’s Gemini API and numpy. After several back and forths, it gave me the code for a simple implementation, with some explanations. You can see the full conversation here. Despite having the “answer”, I chose not to copy and paste the code. I thought through how and where to add the code in my repo and manually typed the code.
Retrieval-augmented generation (RAG)
Let’s walk through my build process, including my missteps.
As a quick refresher, my assistant can scrape websites and summarize content via a team of agents. See the flowchart below for an idea of how it worked before this upgrade.
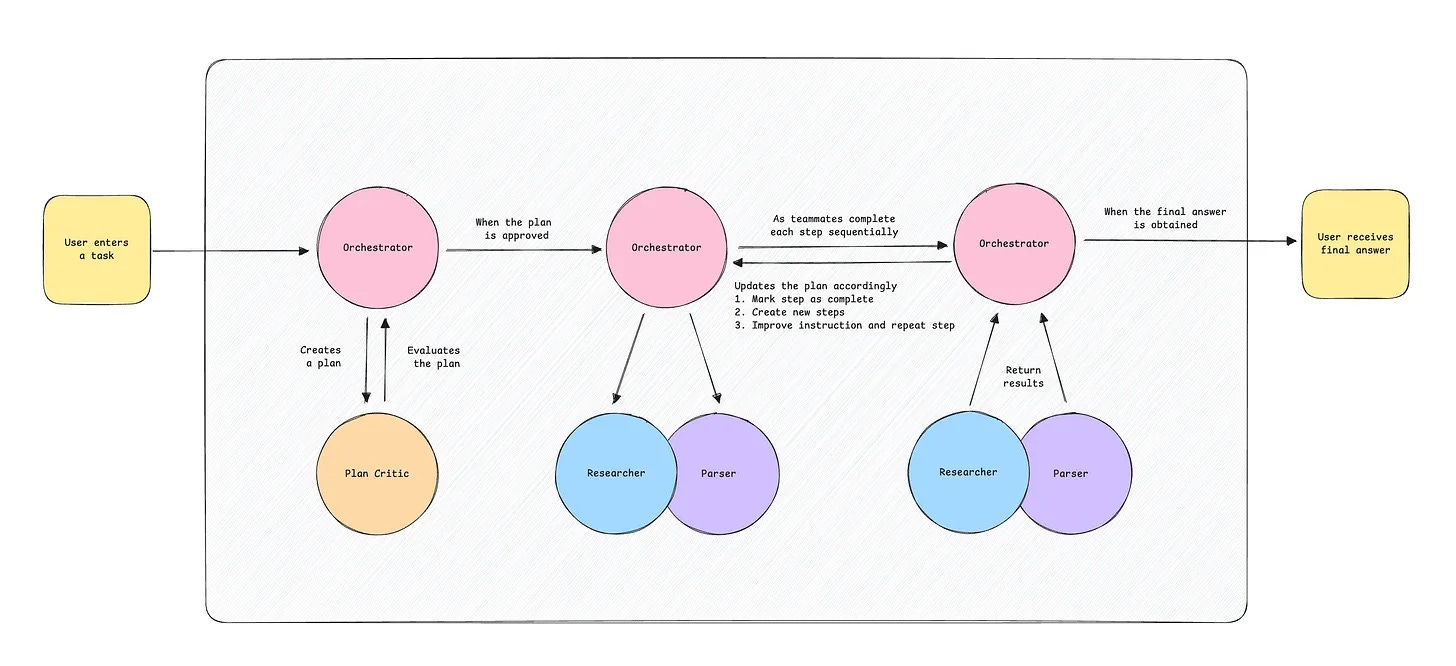
The first step was to figure out where to add a retrieval system and how the user would use it. Given that past tasks cannot be found online and are valuable private information, I thought I would let the user ask about past tasks.
A question then came up:
When should the assistant search for past tasks in the database and when should it search the internet via the Researcher and Parser?
My native first answer was:
Well, that sounds like a classification problem. No problem, I’ll add an LLM call that takes in the user request and classify it as “past tasks” or “new task”.
So I stuck a new LLM call right after receiving the user’s task. If it classifies the task as “past tasks”, the code will retrieve information from the database and generate a response based on the information. Otherwise, the code would continue as is, creating a plan for the team of agents and carrying it out. Done! I completed this in about an hour or two, the RAG was working, and I was ready for lunch.
Not so fast.
While it (sort of) worked, it didn’t feel like the right way to add RAG to the AI assistant. The RAG and the team of agents were separate components. Being a simple function call, the RAG didn’t have a chat history (i.e. it doesn’t know previous messages in the chat) but the user interface is a chat! Also, what if the user enters a task that was done before? Instead of repeating the task, which includes time-consuming scraping and parsing and costs more to execute, the assistant should simply retrieve the previous task and answer the user. And selfishly, the code became too messy and ugly, which hindered future development. Just look at this monstrosity:
I had to rethink the architecture.
Instead of having the RAG as a separate component, why not make it another agent? A Retriever agent. The Orchestrator will always get the Retriever to search through past tasks and results first. If the task was done before, the Orchestrator can more quickly update the user. If nothing relevant is found, the Researcher and Parser will find the information online. The code and flowchart would look a lot neater too. Look at this beauty:
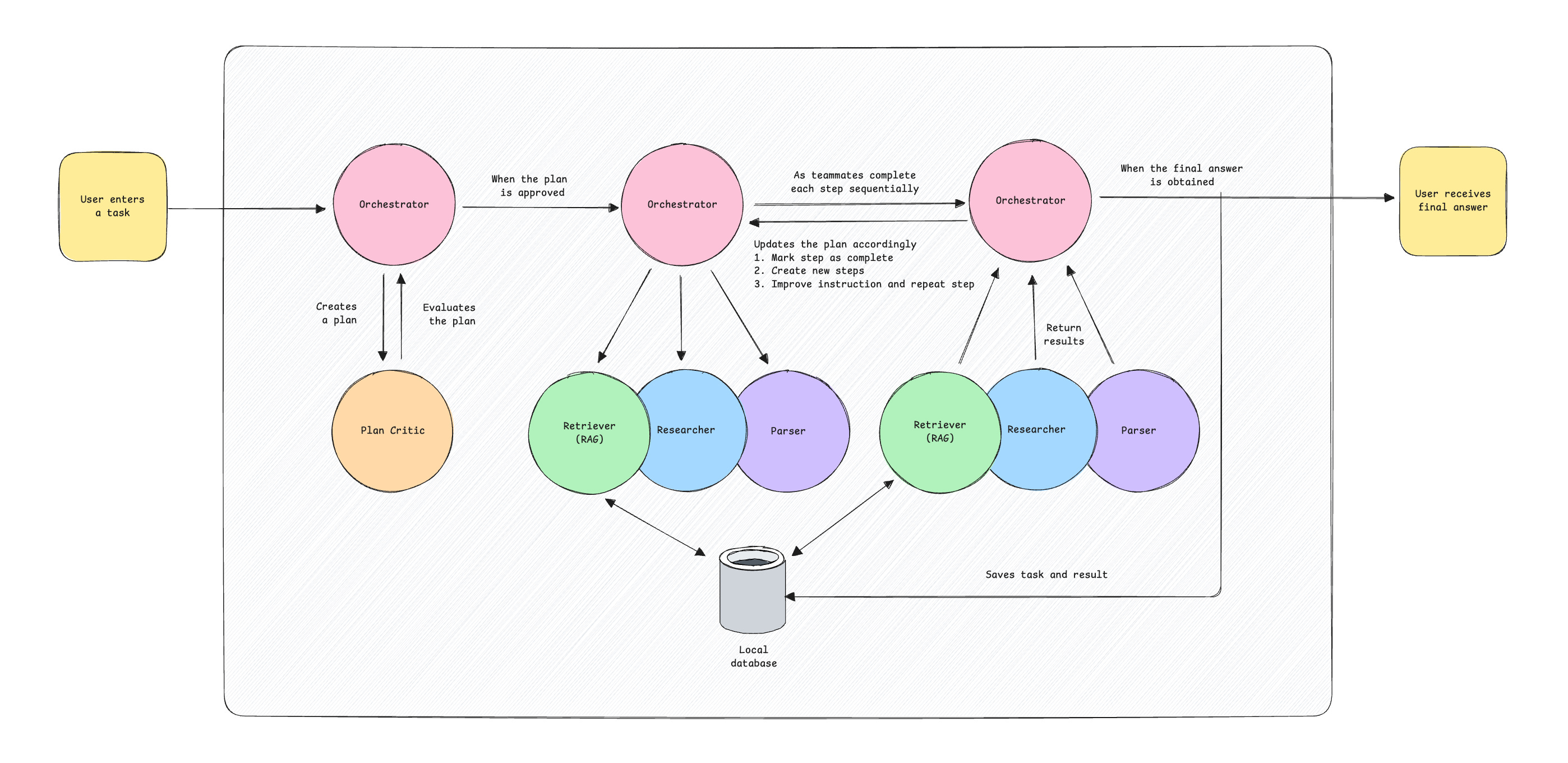
Let’s walk through how the upgraded assistant works:
The Orchestrator receives a task from the user, such as “summarize the first post on hn”, and comes up with a plan for the team.
The Plan Critic evaluates the plan and suggests improvements, up to three times.
After the plan is approved, the teammates work through each step sequentially.
The plan always starts with the Retriever. It searches for relevant information from a local database, which stores previous tasks and results. If it finds something, it passes the information to the Orchestrator.
If no relevant task or result is found, the Researcher scrapes a given website and the Parser extracts specific information or summarizes the content. This could be repeated a few times, depending on the task.
After each step, the Orchestrator reviews the result from the respective teammate and updates the plan until the task is completed.
The Orchestrator informs the user of the answer.
The completed task and result are saved to the local database as text documents and embeddings.
One downside of this setup is that retrieving information about past tasks and results takes a few seconds longer than before because there are a few additional steps: The Orchestrator has to come up with the plan first; the Plan Critic has to evaluate the plan at least once; and after the Retriever returns a response about its search, the Orchestrator has to process the retriever’s response before returning the answer (four LLM calls vs two before). But I think the trade-off is worth it overall.
Here are some examples I tried:
The first task was:
summarize the top post on hn

The Retriever found no relevant past summaries, so the Orchestrator got the Researcher and Parser to work on web scraping and parsing. The result was:
The top post on Hacker News is titled "gRPC vs. REST: Understand gRPC, OpenAPI and REST and When to Use in API Design". The post discusses the differences between gRPC and REST APIs, and provides guidance on when to use each. You can read the full article here: https://cloud.google.com/blog/products/api-management/understanding-grpc-openapi-and-rest-and-when-to-use-them
The AI assistant found the correct post but it “summarized” the post by using only the title. It did not scrape the website and summarize the content. I updated the prompts a little so that the AI assistant would be more thorough for subsequent tasks.
The second task was, again:
summarize the top post on hn

This time, the Retriever found a relevant task (the one above), and the assistant returned that information.
The top post on Hacker News on 2024-07-27 was titled "gRPC vs. REST: Understand gRPC, OpenAPI and REST and When to Use in API Design". This post compares gRPC and REST APIs, offering guidance on choosing between them for API design. You can read the full article here: https://cloud.google.com/blog/products/api-management/understanding-grpc-openapi-and-rest-and-when-to-use-them
I was using only a vector search to find the tasks and results relevant to the user's request. To improve the performance, I might want to programmatically filter the past tasks by their date metadata before performing the vector search. But for this simple prototype, the former seems to work fine.
The third task was:
summarize the second post on hn

The Retriever found two tasks that summarized the top post on Hacker News (the above two) but not the second top post as requested. So, the AI assistant proceeded with the steps involving the Researcher and Parser to get the information needed. This time, it summarized the website content, and not just the Hacker News post title.
Byran Huang documented their creation of a fully open-source laptop from scratch at https://www.byran.ee/posts/creation/. The laptop features a 4K AMOLED display, a Cherry MX mechanical keyboard, and runs demanding applications like Minecraft and large language models. The project includes detailed documentation, schematics, and source code, showcasing a remarkable feat of engineering and open-source collaboration.
It is working pretty well!
Product design > Technical implementation
After this exercise, I realized it is fairly straightforward to implement a RAG system. I don’t mean it is easy, though. I stumbled several times along the way, even with this basic retrieval system. And I have not touched on the more advanced areas, such as using a vector database, finding the most appropriate chunking method, and optimizing the performance. It’s hard. But with the help of ChatGPT, Perplexity, and Google, I was able to get something working by myself.
The harder aspect, it seems to me, is the product design. When is RAG necessary? When is RAG better than relying on the model and context? Most importantly, when would RAG improve the user experience?
Notion AI searches through a user’s notes to provide accurate answers to questions about his notes. Intercom’s Fin sources relevant help articles to assist customers with their inquiries. Our health insurance AI assistant finds information in health insurance policies to help Singaporeans make informed choices. In these examples, no LLM could have done the job itself. LLMs cannot access users’ private information or browse the web. RAG enables the apps to provide factual, accurate answers rather than incorrect hallucinations. If your app needs to be objective rather than creative, consider adding RAG.
What other great applications of RAG have you seen?
Jargon explained
I came across these terms several times this week while reading about DeepSeek.
Supervised Fine-Tuning (SFT): This is a technique to improve a model by giving it high-quality examples of input and output. For example, GPT-4 was given human-generated examples of questions and answers to learn how to behave like a conversational assistant before it could be used in ChatGPT. SFT could be used to refine a model’s general performance, make a model more specialized, correct its weaknesses, or improve safety.
Reinforcement Learning (RL): This is another technique to improve a model. RL helps the model learn by rewarding it for desired outputs and punishing it for undesired outputs. In the case of ChatGPT, human evaluators rated the model’s responses and the model was trained to prefer higher-rated responses because OpenAI wants ChatGPT to generate responses humans prefer. Because human evaluators were involved, it is considered Reinforcement Learning from Human Feedback (RLHF).
Mixture-of-Experts (MoE): This is an architecture (not a training technique) to improve speed, costs, and performance by using multiple specialized sub-models ('“experts”) to tackle different parts of the problem. Instead of using all the experts for every input, the model selects a few relevant ones. This makes the AI generate responses faster, allows it to handle bigger and more complex tasks, and lowers computing costs while still producing high-quality results.
Honestly, while I kind of know these terms now, I still do not truly understand them. I would need to try them but that is not my goal for now.
Interesting links
ReAG: Reasoning-Augmented Generation: Alan Zabihi described the issues with RAG and suggested a different approach.
The Short Case for Nvidia Stock: While this is a stock analysis, it explains many interesting parts of the AI industry, such as how DeepSeek could train a model comparable to GPT-4o at 1/20th the cost.
The Lessons of Fin for This Generation of ‘AI Assistants’: Sam Lessin, cofounder of the now defunct AI assistant startup, shared his lessons from building Fin.
This Rumor About GPT-5 Changes Everything: Alberto Romero made a strong case for why GPT-5 might already be here but not available to the public. More interestingly, it got me thinking about how AI models are already very capable but we don’t have good enough products that leverage them well.
Recent issues



If you notice I misunderstood something, please let me know (politely). And feel free to share interesting articles and videos with me. It’ll be great to learn together!