
AI10: Introducing Muse, your AI writing companion
Building an AI chat assistant to solve my own problem, and the challenges along the way


I was excited to finally share a prototype that you can immediately try. But as I had expected in my last newsletter, the boilerplate stuff held me back.
Nevertheless, this show must go on!
Let me introduce my latest prototype, explain why I built it, and share the challenges I’m experiencing (perhaps you can help me with them!)
Introducing Muse
As a writer and marketer, I hate the first wave of AI writing tools.
They all claim to generate articles instantly that can evade AI detectors and rank highly on Google. We can even upload our old articles to generate articles in our tone and voice.
But like AI, they lack a soul.
The soul of the writer. The experiences of the writer. The emotions of the writer.
In case it’s not obvious from this newsletter, I love AI. But I hate how AI is used in some ways.
So, how have I been using AI for my writing?
As I shared previously, I have been using ChatGPT to assist me in my writing, not replace myself. I use it to find suitable words, get alternative phrasing, and check my language.
Here’s a trivial example. In the last issue of Alfred Intelligence, I originally had this paragraph:
Anthropic finally dropped a new model, Claude 3.7 Sonnet, which seems even better at coding than Claude 3.5 Sonnet, which was already great at coding. The team also launched a command line tool, Claude Code, which uses the new model to work on coding tasks on our computers.
I didn’t want to use “which” repetitively, so I asked ChatGPT for help.

I didn’t copy ChatGPT’s suggestion wholesale but instead learned to rephrase “Claude 3.5 Sonnet, which was already great at coding” to “the already impressive Claude 3.5 Sonnet”.
I have countless other examples like this. For every essay I write, I ask ChatGPT for help about 10 to 20 times. That is a lot of copying, switching tabs, pasting, switching tabs, and editing.
Hence, I built Muse.
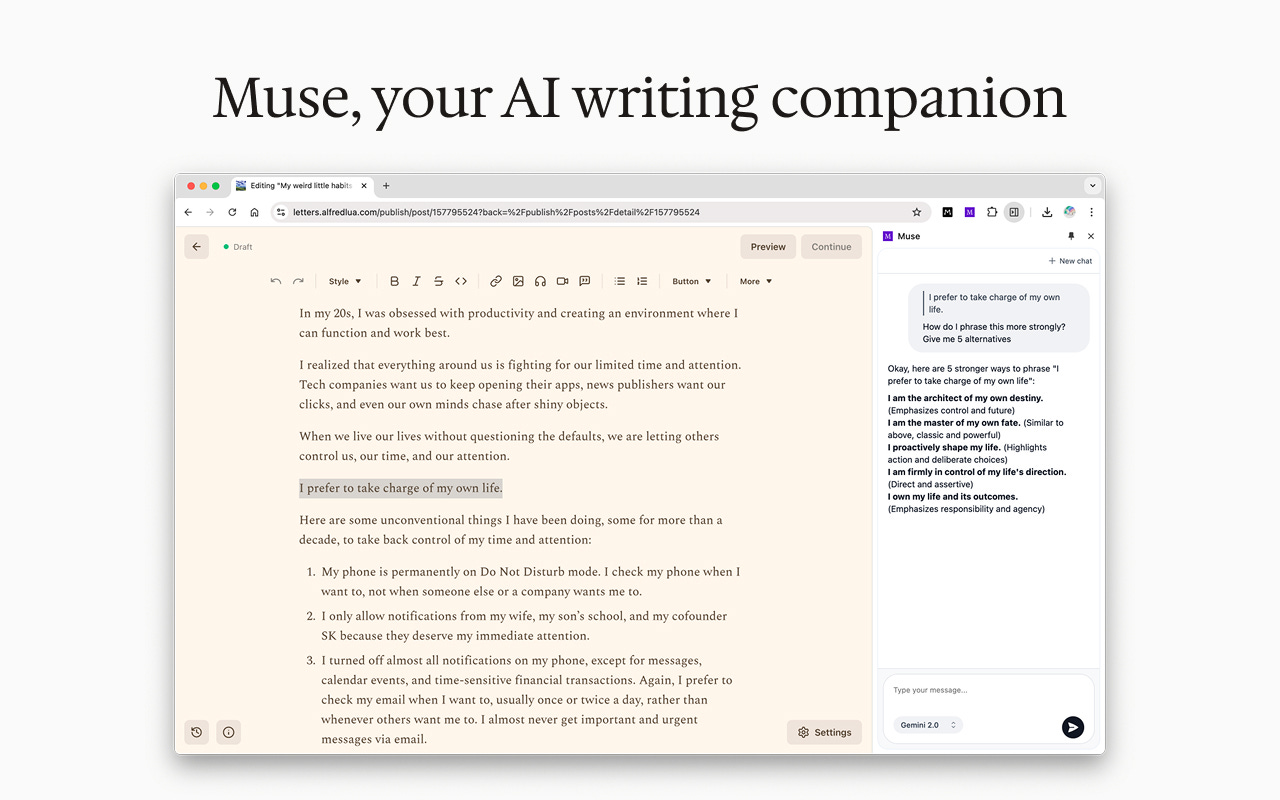
Muse is an AI writing companion that can help you where you write, say Substack.
Muse opens a side panel on your Chrome browser so you can chat with it in your preferred writing editor. You do not have to use a separate web app and then copy and paste into your editor.
When you select text in your draft, Muse adds it to the chatbox, saving you from copying and pasting repeatedly.
You can chat with Google Gemini 2.0 Flash, OpenAI’s GPT-4o mini, or Anthropic’s Claude 3.5 Sonnet.
Most importantly, it keeps you and me in the writer’s seat.
I love the process of writing. I write to share my unique personal experiences and emotions. And I never want AI to generate entire essays on my blog. How sad would that be?
But AI, having studied the internet, is a great writing companion, assistant, and coach.
This is why I built Muse the way it is.
To clear a little fog when we are stuck.
To shine some light when we are lost.
And to spark fresh ideas when we are empty.
Not to replace the entire journey.
I hope this philosophy that I built into Muse resonates with you. If you are interested, I would love to let you try it soon!
Challenges
I wish I could share a link to Muse on the Chrome Web Store for you to download and try it immediately.
But I am still waiting for the Chrome Web Store to approve it, and I am stuck deploying my backend.
Chrome extension approval. Because Muse gets AI responses from my backend, it requires “host permissions”. The Chrome Web Store stated that extensions with host permissions are subjected to an in-depth review, which could take weeks! Does anyone know any way around this? Will updates to the extension take weeks to be approved too?
Backend. My backend is a Python script that simply calls the Google Gemini API via LiteLLM. I tried using AWS Lambda to host it but the lambda has been timing out and running out of memory. I’m not sure why this is happening, even though it is a simple script and it loads quickly locally. Lee Robinson from Vercel suggested their Fluid Compute, which seems interesting. But I’m still worried my script is more complicated than it should be and might cause me a hefty bill. Does anyone have experience deploying a backend for a simple AI chat app?
(Update: Since I wrote this draft, I managed to get my backend working with AWS Lambda. My cofounder SK made me realize I had misunderstood AWS Lambda and serverless functions. Serverless functions should be small, self-contained functions but my backend has huge packages like FastAPI and LiteLLM. So yes, my intuition was right! My code was more complicated than it should have been. Once I simplified my backend script to call the Gemini API directly via HTTP, it works with AWS Lambda. Switching to Vercel or other platforms would not have solved the root cause.)
My goal is to put my tools in people’s hands as quickly as possible. So, I intend to share Muse for free. For a start, you won’t have to pay or even register to try Muse.
But, of course, if you are keen to support Muse, let me know!
I can’t wait to let you know when it’s finally ready.
Jargon explained
Servers vs serverless functions: I’m not sponsored by AWS (though that doesn’t sound like a bad thing!) but SK suggested I look into AWS Lambda for my simple backend. It is one of the few serverless compute services. What that means is we can run code, like my backend Python script, without the hassle of setting up and managing servers. Also, we only pay for what we use, which is whenever we call the function. With servers, we pay as long as the servers are up and running, even when they are not executing any functions. Besides servers and serveless, Vercel introduced another alternative, Fluid Compute. Lee Robinson made a great explainer video about it.
LiteLLM: If you want to let your users switch between models, you would have to write code for each of their APIs. While that alone is tedious, they also return the responses in slightly different formats. OpenAI returns the response in
completion.choices[0].messagewhile Gemini usesresponse.text. LiteLLM lets you work with 100+ LLMs using OpenAI’s input and output format. After hardcoding for different APIs for my AI assistant and trying LiteLLM this week, I realized how much work LiteLLM saves developers.Type hinting: In Python, we can specify the expected data types of variables. Below is an example, where
x,y, and the output are expected to be integers. Type hinting makes our code easier to read and enables our IDE to suggest autocompletes. For example, once we typeadd(, our IDE would suggest we enter a value forx.
def add(x: int, y: int) -> int:
return x + y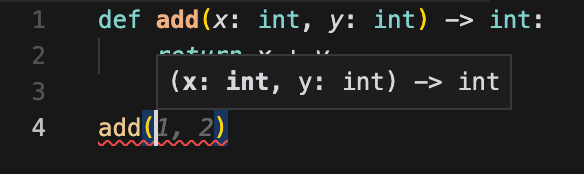
Interesting links
Hallucinations in code are the least dangerous form of LLM mistakes: Simon Willison provides some tips on reducing hallucinations in generated code.
Model Context Protocol (MCP): I shared about MCP in AI4 but it became popular again this week on Twitter. Here’s a good explanation by Matt Pocock. Honestly, while I understand the concept and its benefits, I still don’t understand how I’d actually use it. It seems easy to use locally but hosting a MCP server for others to use seems hard (especially since I’m already struggling to host my simple backend!)



