
Alfred Intelligence 7: A practical guide to AI evals for hackers
You built an AI app that can generate responses for your users; then what?


If you are new here, welcome! Alfred Intelligence is where I share my personal notes as I learn to be comfortable working on AI. Check out the first issue of Alfred Intelligence to understand why I started it.
Before this week, I had no idea what evals (shorthand for “evaluations” in AI) are. I thought I had a rough idea until I tried doing evals this week. And, well, I got stuck immediately. A humbling experience, indeed. So this past week was a crash course on evals. I went from (almost) zero to experimenting with three evaluation methods and building a dashboard to view the evaluation results—in about two days.
My goal for this issue is to help you quickly grasp the basics of evals by walking through my accelerated learning journey. This is not a comprehensive guide to evals. If you are looking for a step-by-step guide to creating an evaluation system for a company, I recommend Hamel Husain’s Creating a LLM-as-a-Judge That Drives Business Results.
My 9 steps to learning basic AI evals
As a bit of context for those who haven’t been following my AI learning journey, I have been building an AI personal assistant to learn about the technologies behind agents. While this is just an exercise, I keep things as practical as possible because I eventually want to build a product. Instead of evaluating my AI responses using the generic criteria in most articles, I pretend this would be an actual product and evaluate the responses based on what I deem is good. For this week’s project, I want to find the best assistant architecture out of three.
1. Read up on evals
Even though I have built LLM apps, I had only done vibe-based evaluations. That’s a nicer way of saying “I went by feel.” That’s all I knew about evals.
To quickly get up to speed, I used Perplexity to help me find relevant articles. Most of them were too superficial. But with follow-up questions, Perplexity generated some basic evaluation prompts that came in handy afterward.

I remembered Hamel Husain and Eugene Yan often tweet about evals, so I went to their blogs to look for related articles. I was not disappointed. Their articles (listed at the bottom) gave me a deeper overview of evals, with Hamel’s step-by-step guide being the one I largely followed in my experiments.
After my initial reading, it seemed that two of the LLM-as-a-judge methods, single score and pairwise comparison, would be most relevant to my project.
2. Prompt in ChatGPT
I still wasn’t ready to jump into coding. Instead, I tested the single score method in ChatGPT to check whether it would work for my use case. I used a simple prompt with no examples:
Evaluate the response to the query '(task)':
Response: (response)
Score 1-5 for correctness (5=factually accurate), relevance (5=fully on-topic), and comprehensiveness (5=broad and deep information).
Format: {correctness: score, relevance: score, comprehensiveness: score}ChatGPT returned something like this:
{correctness: 4, relevance: 4, comprehensiveness: 3}
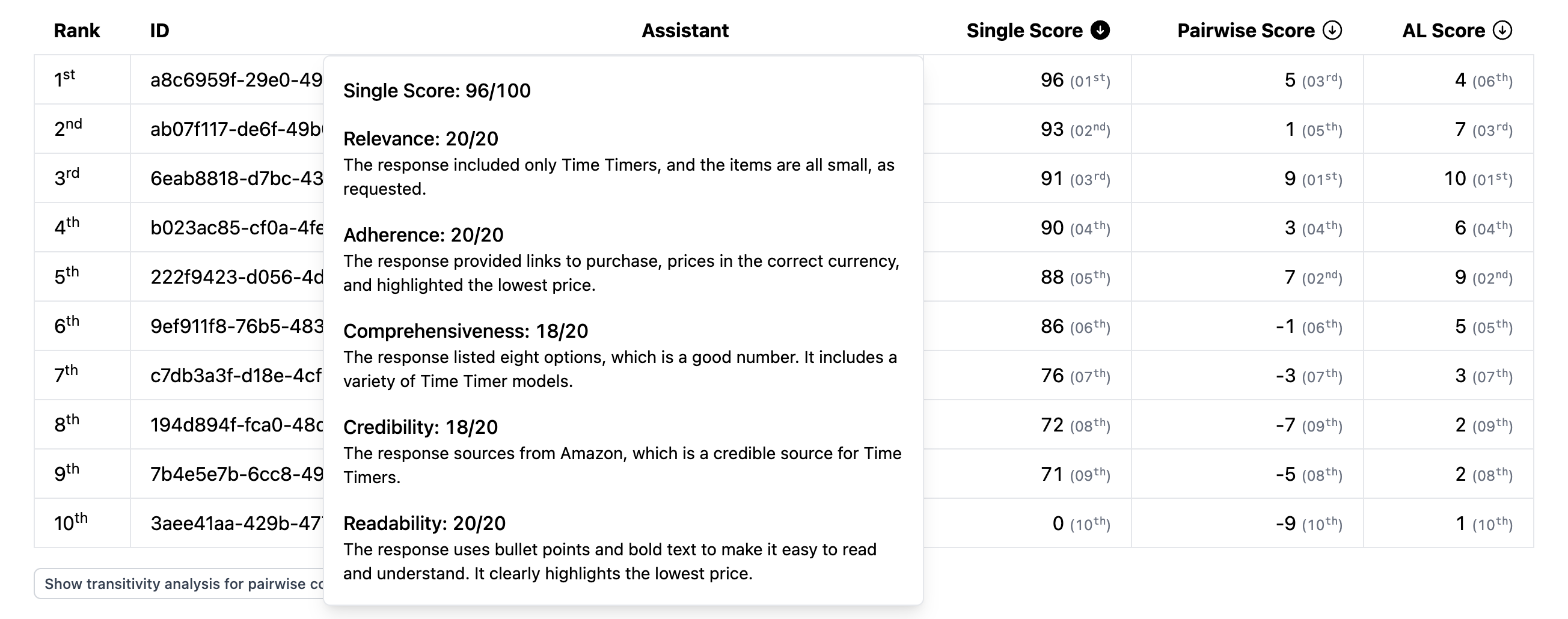
Correctness (4/5): The prices and product names seem reasonable, but without verification from actual purchase links, there's a possibility of inaccuracy.
Relevance (4/5): The response provides various Time Timer products with prices, which is helpful. However, the query specifically asked for a small Time Timer, and the response includes multiple sizes without clear differentiation.
Comprehensiveness (3/5): While the list covers many Time Timer options, it lacks direct purchase links and store sources, which were explicitly requested. Also, the lowest price is highlighted but not contextualized in terms of features or availability.
Even with such a basic prompt, GPT-4o gave a reasonably good evaluation. This gave me some confidence that this method could work. Now, I’m ready to write code.
3. Create a Python script to evaluate one AI response
I’m not great at coding, so I started with a simple program: a Python script that can evaluate a single AI response against its task and print the evaluation in Terminal. Well, actually Cursor created the script, not me. It pretty much one-shotted the script:

When this worked, I scaled it up—just a little.
4. Upgrade the script to evaluate 10 responses
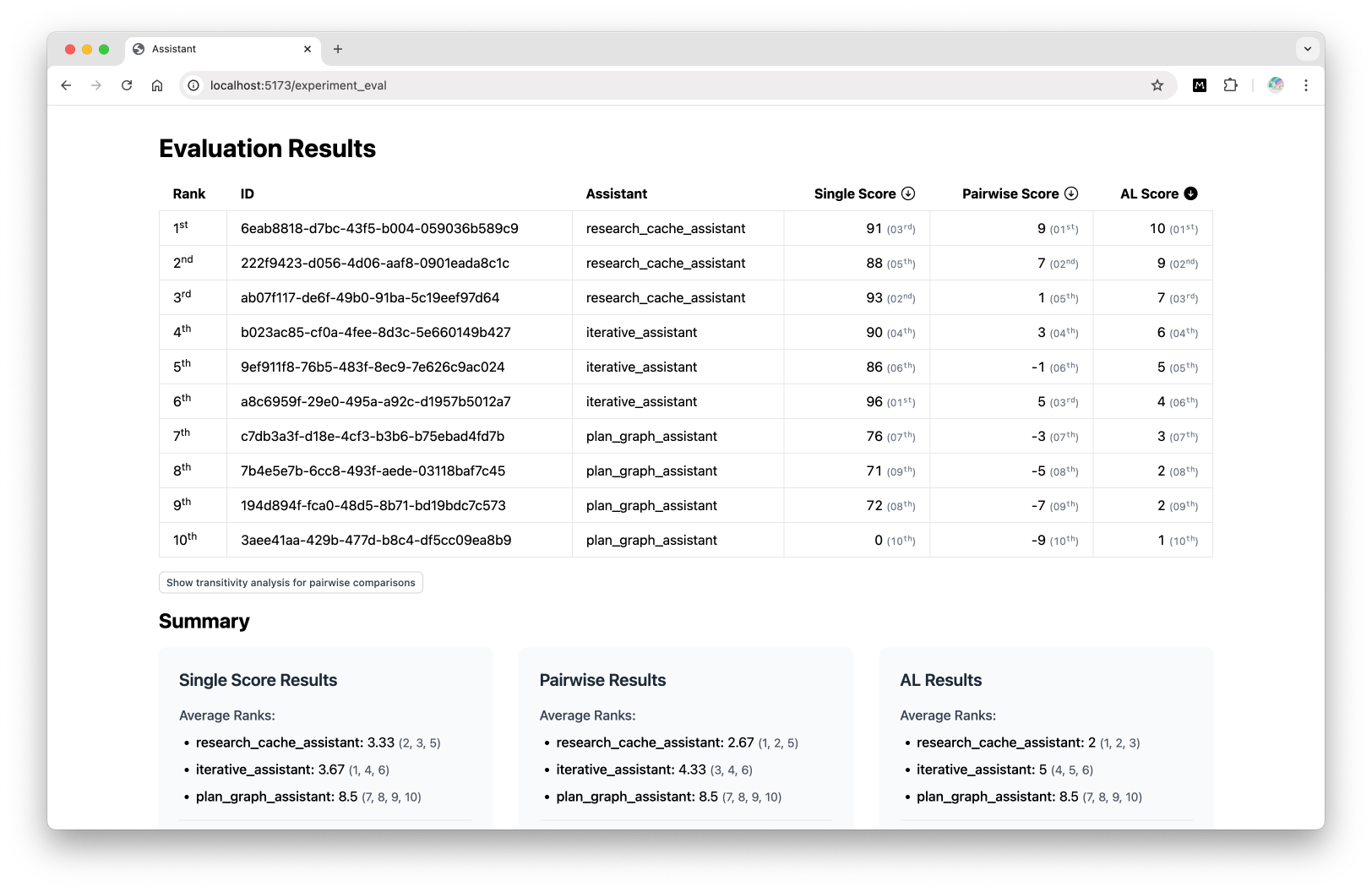
I pulled 10 responses for a specific task from our Supabase, where we log the tasks and responses. Each response has an ID and the assistant that generated it, which I’d need later.
Then I upgraded the script to cycle through the list of responses with a for-loop. But I still printed the evaluation in Terminal, which looked something like this:
1. (response_id) - (assistant) - (score)
2. (response_id) - (assistant) - (score)
3. (response_id) - (assistant) - (score)At this stage, I was only concerned about the score and ignored the evaluation explanations.
5. Repeat steps 1-4 for the pairwise comparison method
Again, I used a basic prompt in ChatGPT:
Compare Response A and B for the task '(task)':
Response A: (response)
Response B: (response)
Which is a better answer from a personal assistant? Consider accuracy, empathy, and conciseness.
Final answer: 'A' or 'B' with a 50-word justification.Notice I didn’t optimize the evaluation criteria (“accuracy, empathy, and conciseness”) at this point. I know it’s something I’d do later. I just wanted to see if this method would make sense.
ChatGPT returned:
Final answer: A
Response A is better because it clearly lists multiple options with prices and highlights the lowest price, directly addressing the user's request. It is concise, easy to scan, and requires minimal effort from the user. Response B, while providing links, lacks price details and requires extra clicks to compare options.
Great, it worked! I then created another Python script for this method. But pairwise comparison is different from the single score method because it has to do a lot more evaluations. For 10 responses, it has to compare 45 pairs of responses. This caused me to hit Google Gemini API’s rate limit so I added a time delay between each API call:
time.sleep(5) # The rate limit is 15 per minute while this is 126. Improve the prompts
Once I was able to programmatically evaluate 10 responses using both methods, I made the criteria in the prompt more detailed and included two examples—one good and one bad—each.
CRITERIA = """
- Adherence: Does the result satisfy the task? If the user asked for links, the result should include links.
- Another criteria:
- Another criteria:
"""
SINGLE_SCORE_EXAMPLES = """
<examples>
Task: (task)
Response: (good response)
Evaluation: (evaluation, in the format I want)
---
Task: (task)
Response: (bad response)
Evaluation: (evaluation, in the format I want)
</examples>
"""
PAIRWISE_EXAMPLES = """
(Pairwise comparisons require two responses per example, so I created separate examples.)
"""7. Compile the results in a Google Sheet
I manually copied the evaluation results from Terminal and pasted them into a Google Sheet to more easily compare them and share them with my cofounder SK.

After putting it together, I realized the static spreadsheet is not great for viewing the evaluations. I could hack together something better by using notes and multiple tabs but it still wouldn’t feel great. Armed with Cursor, I decided to build a dashboard to display the information.
8. Build a dashboard
I first updated the evaluation scripts to save the results as JSON, instead of printing them to Terminal. Then I created a simple Vue app (with Tailwind) to display the results nicely.
Here are some of the cool features:
Clicking on a score column will sort the responses by the respective score in decreasing order.

Hoving over the response ID shows me the formatted response so that I can quickly see what the response looks like to the user.

Hovering over any score will show me the explanation for the score.

Because it’s an app and I have Cursor, I could easily add a summary at the bottom.




9. Add more analyses
“Expert” evaluation
Even with the improved prompts, the two methods produce quite different rankings of the responses. So I added one more method: my “expert” evaluation, based on the same criteria (which I wrote). I ranked the responses from one to 10, which was doable for 10 responses but would be harder for more responses.
My evaluation also gave different rankings but was more similar to the pairwise comparison’s rankings than the single score’s rankings. For now, it seems that pairwise comparison is closer to our “expert” evaluation than the single score method.1
Transitivity analysis
For the pairwise comparison method, I wanted to check that there are no contradictions in the comparisons. For example, if A is better than B and B is better than C, A must also be better than C. This is known as transitivity (a term Cursor taught me).
Within a handful of prompts, I created an analysis to show that there are no transitivity violations (the LLM judge did well!) and displayed the relationship for every response. Again, for easy viewing, I can hover over any response ID and see the formatted response.

AI-powered learning
I’m still in awe at how much AI helped me with this project. All of the above, excluding the reading, took me only about eight to 10 hours. I have never been a professional developer! Without ChatGPT and Cursor, I’m not sure I’d even dare attempt something like this. When I said “I created this, I created that” above, what I meant was I described what I wanted in English and Cursor generated the code. Cursor was responsible for around 95% of the code. Google and Stack Overflow might allow me (with enough persistence) to create a much simpler version of this. But even that would likely take me at least an entire week.
But just because something is easy does not mean it is the right thing to do. The danger of this newfound power is that I might keep doing little cool stuff without actually moving toward my goal. For example, optimizing the prompt to get better evaluations is more important than adding the transitivity comparison graph. But the latter looks and feels so much cooler.
To be fair, though, adding the transitivity comparison graph, once I had the transitivity analysis, took me less than five minutes. Even producing the transitivity analysis took me less than five minutes. Both were extremely quick and low “cost”. If it’s just this single distraction, the “cost” was worthwhile. But I’m wary that I’d go down a distraction rabbit hole if I do not regularly take a step back and reflect (or write, like I’m doing now).
Next steps
Upon reflection, these feel like the appropriate next steps:
Improve my evaluation prompts so that the two methods align more closely with my “expert” evaluation.
Scale this up further to evaluate more than 10 assistant responses and for more than one task. This will inform us which is the best assistant based on the LLM judges, a more data-driven approach than vibe-based evaluation.
Pull the responses from our database automatically, instead of manually (I was afraid of accidentally deleting or incorrectly overwriting parts of our database).
Optimize my code to speed up the pairwise comparisons. The number of comparisons grows quadratically. 10 answers require 45 comparisons; 100 answers require 4,950 comparisons. But assuming there will be no transitivity violations, we can skip many comparisons. If A is better than B and B is better than C, I don’t have to compare A and C. The number of comparisons could grow linearly, instead of quadratically, using the tournament approach or hierarchical ranking2.
Decide which assistant is best and if it is good enough. Otherwise, we will need to create another assistant (e.g. different prompts, tools, architectures) to see if we can get better results.
(Since writing this draft, which has forced me to consider my next steps, I upgraded my program to automatically pull all responses for a selected task from our database and evaluate them. I also updated the pairwise comparison to use merge sort (assuming there won’t be transitivity violations), which drastically reduced the number of comparisons. For 40 responses, the duration dropped from 65 minutes to about 18 minutes.

Jargon explained
Harness: I came across this concept while reading about evaluations, specifically the Holistic Agent Leaderboard. A harness is essentially a tool to easily test an AI model or agent against multiple evaluations in a controlled and automated manner. More from ChatGPT. OpenHands also has an evaluation harness.
Trace: I saw this term while researching LangSmith and saw it again in Hamel’s article. He gave a great explanation: “tracing is a logical grouping of logs. In the context of LLMs, traces often refer to conversations you have with a LLM. For example, a user message, followed by an AI response, followed by another user message, would be an example of a trace.” I would add that in the case of an agent, we would want to also include the function call logs in the trace to debug any tool errors.
Active learning, query-by-committee, consensus voting: I encountered these in the same Hamel’s article. The way I understood them is:
Active learning is where the model identifies ambiguous data points that would most improve performance, for a human to label or evaluate. This is useful when it is not feasible to label or evaluate all data points manually.
Query-by-committee is a technique to identify the data points for human labeling or evaluation. Multiple models vote on the generated outputs, and the ones with the most disagreement are selected.
Consensus voting is where multiple people vote on the model’s outputs to determine which is the best output to reduce errors, especially from a single human evaluator.
Interesting links
A trick to create reasoning models: Add “wait” when the model stops thinking so that it will think some more and give better responses.
AI hedge fund: While I have been working on an AI personal assistant, virat built an AI hedge fund team with a market data agent, quant agent, risk manager agent, and portfolio manager agent.
Deep Research, Deep Bullshit, and the potential (model) collapse of science: Gary Marcus argues that AI outputs, which look good but are often wrong, will flood the internet and cause future models, which train on this new information, to be worse. The internet is already filled with garbage but AI will make it even easier and faster to produce more.
Evaluation articles:
Recent issues



If you notice I misunderstood something, please let me know (politely). And feel free to share interesting articles and videos with me. It’ll be great to learn together!
According to Hamel, I should update my evaluation prompt and try to get the LLM evaluations closer to my “expert” evaluation.
Cursor shared these two approaches with me but I have yet to try them out yet, so I can’t say I know what they are.